FB2Droid - A Novel Malware Family-Based Bagging Algorithm for Android Malware Detection
本文最后更新于:1 个月前
摘要
随着 Android 恶意软件应用程序数量持续高速增长,检测恶意软件以保护系统安全和用户隐私变得越来越紧迫。每个恶意软件应用程序都属于特定家族,恶意软件家族之间存在数量差距。如果很好地利用恶意软件家族信息并采用某些策略来平衡样本之间的变异性,则检测的准确性可以得到提高。此外,基础分类器的性能有限。如果可以采用集成分类器或集成方法,检测效果可以进一步提高。因此,本文提出了一种新的基于恶意软件的基于家族的Bagging算法,用于 Android 恶意软件检测,称为 FB2Droid。首先,从安卓应用程序包中提取了五个特征。然后,将解压特征选择算法用于特征选择。接下来,我们根据不同恶意软件系列设计了两种不同的采样策略,以缓解数据集中的样本不平衡。结合两种取样策略,改进了传统的Bagging算法,以集成分类器。在实验中,使用了几个分类器来评估这两种采样策略。实验结果表明,建议的取样策略和改进的Bagging算法可以有效地提高这些分类器的检测精度。
1、简介
近年来,Android操作系统发展迅速,是智能手机操作系统使用最广泛的系统。根据《全球统计》最近的一份报告 。截至2019年4月,Android设备在所有智能手机用户中的市场份额最高,占74.85%。除了它的受欢迎程度,它也引起了恶意软件开发者的注意。关于 Android 恶意软件,根据 McAfee 移动威胁报告 2020,2019 年第 4 季度检测到的移动恶意软件总数超过 3500 万。恶意软件的惊人增长对用户构成巨大威胁。因此,检测恶意软件和保护用户安全迫在眉睫。
随着机器学习算法的发展和普及,它们被广泛应用于Android恶意软件检测领域。基于机器学习的恶意软件检测主要包括以下步骤:
- 数据收集和整理,以及分析良性和恶意样本,并提取特征;
- 使用特征选择算法筛选提取的特征;
- 训练分类模型;
- 使用分类模型检测和判断未知样本
根据不同的特征提取方法,Android恶意软件检测可分为静态分析和动态分析。
静态分析使用逆向工程来分解 Android 应用程序包 (APK),而无需安装和执行应用程序,然后从代码和其他文件中提取特征。与静态分析不同,动态分析需要运行应用程序,然后收集有关运行内容以提取特征的信息。这种方法在识别恶意活动时可以达到很高的准确性,但实时运行监视器需要很长时间和巨大的资源。相比之下,静态分析技术由于资源消耗低、代码覆盖率高而得到广泛应用。
安卓恶意软件检测问题本质上是一个分类问题。随着恶意软件的飞速发展,各类恶意软件也越来越多。根据恶意软件的行为和特征,恶意软件可以分为不同的家族。但是,不同恶意软件家族的发展不平衡,样本数量差异很大,导致检测不平衡。换句话说,某一类型的大量样品导致分类器对此类样品的"偏差",从而影响检测效果。传统分类算法在平衡数据集中取得了良好的效果,但实际数据集往往不平衡,传统算法对不平衡数据敏感,检测效果较差,如 SVM 和 Rf 。数据不平衡表现在两个方面:
类间不平衡,其中数据集中一个类的样本数量明显少于其他类别的样本数量
课内不平衡,其中一个类及其子类中的样本数不平衡或一类数据呈现多个小的分离术语
由于传统分类器以整体分类精度为学习目标,在这种情况下,要获得更高的分类精度,势必导致分类器过分关注大多数类样品,从而降低少数类样品的分类性能。目前,大多数恶意软件检测方案忽视了内部的不平衡,即恶意软件内部各种软件家族之间的不平衡,导致训练有素的分类器对样本量大的家族具有更好的检测性能,但对样本数量较少的家族的检测性能较低,从而降低了整体检测效率。此外,大多数现有的 Android 恶意软件检测方案仅使用特征和有效性的单个分类器。
因此,为了解决上述问题,本文提出了一种新的基于恶意软件的家族装袋算法,用于Android恶意软件检测。首先,该方案从 APK 文件中提取五个特征,然后使用解压特征选择算法来评估每个特征的重要性,然后选择一些更重要的功特征进行分类器训练和恶意软件检测。然后,根据数据集中提供的家族标签,设计了两种采样策略,以缓解数据集中的类内不平衡。然后,设计策略用于改进装袋算法,以集成分类器以检测恶意软件。实验结果表明,使用基于一些通用分类器的拟议集成方案,恶意软件的检测精度和F-score提高了2.3%和2.0%。
本文的贡献如下:
- 恶意软件的家族信息和类别标签应用于恶意软件检测,并构建了基于恶意软件家族的集成 Bagging 方案,以有效提高恶意软件检测的准确性。
- 考虑到恶意软件家族之间的不平衡,改进了 Bagging 的采样策略。在基于经典 Bagging 算法的随机抽样的基础上,增加了两种取样方法:基于恶意软件家族数量的等数取样策略和基于恶意软件家族信息的取样策略。
- 设计的抽样策略考虑到了恶意软件家族之间的不平衡,可以有效缓解班级内部的不平衡,并充分照顾每个恶意家族。
- 我们设计并进行了多项实验,并提出了有效的实验成果。实验结果表明,建议方案的可行性和有效性。
2、相关工作
Android 恶意软件检测技术分为三类:静态分析、动态分析和混合分析。
静态检测使用相应的分解工具提取程序的静态特性,如语法语义和签名,用于分析,以评估应用安全性和检测恶意软件。
静态分析可以进一步细分。一个是基于签名的恶意软件检测,基于签名的静态分析方法主要使用应用软件的独特签名机制来唯一识别应用程序的签名和特征代码,并将其与已知的恶意软件特征基础进行比较,如果与一致签名匹配,则判断为恶意软件。Faruki 等人提出了 AndroSimilar,这是一种通过提取统计学上强大的特征来检测恶意 Android 应用程序来生成签名的方法。郑等人提出了的 DroidAnalytics,一个基于签名的检测和分析系统,可自动收集、管理、分析和提取 Android 恶意软件,它使用多级签名算法(签名包含方法级别、类级和应用级别)根据 操作码级别语义提取恶意软件特征,与传统加密方法(例如基于 md5 的签名)相比,多级签名方法具有重要优势。但是,该技术存在一些局限性,在用于检测重新包装的恶意软件时,无法高精度地解决问题。而且,随着恶意应用的爆炸式增长,需要不断提取新的恶意应用特征签名代码,这在一定程度上增加了工作量,效率太低。这产生了一种替代静态分析方法,该方法使用多个静态特征来检测恶意软件。为此,可执行应用程序 (APK) 经过逆向工程,从中提取相关特征以进行分析和检测,例如 API 、权限、意图、特征调用图、控制流图。Aorar等人提出了一种名为 PermPair 的新型检测模型,它通过挖掘来自 AndroidManifest 的权限组合来检测恶意软件.xml 应用程序。Niu等人使用函数调用构建函数调用图来分类 Android 恶意软件。本文使用了操作码级函数调用图,这是通过对操作代码 (OpCode)的静态分析获得的。然后,作者应用长期短期存储器(LSTM)来检测应用程序。
动态分析不同于静态分析,可实时监控程序的运行,以查找和检测程序的恶意行为。其中,动态特征包括网络流量 。系统调用和资源消耗。Vinod 等人提出了基于系统调用的 Android 恶意软件检测方案,结果在五个数据集上进行验证。RoughDroid 建议采用软盘分析技术,可直接在智能手机上发现 Android 恶意软件应用程序。
但是,动态分析需要监控移动设备或模拟器上的应用程序以提取特征,这很费时。因此,一些学者将静态分析与动态分析相结合,进行混合分析。在“A hybrid detection method for android malware”,作者提出了一种混合检测方法,对静态检测检测的这些可疑应用进行动态检测。在作者从良性和恶意应用程序(如 API 呼叫序列、系统命令、显性权限和意图)中汇编了静态和动态特征。然后,他们使用深层神经网络对应用程序进行分类。在 [31•,作者应用网络相关特征和活动大拉姆构建一个检测方案,以解决基于机器学习和混合分析的Android恶意软件家族分类问题。提出了广泛的特征集,包括网络相关特征和活动大拉姆。本文提出的方案属于静态分析。
随着 Android 恶意软件的快速发展,有多种不同类型的恶意软件,根据恶意软件的特点可分为不同的家族。恶意软件家族的分类也是恶意软件检测的重要组成部分。但是,数据集中存在多种恶意软件家族,它们之间的分布不平衡,因此很难检测到恶意软件。因此,许多学者已经开始关注这一方向,希望通过对恶意软件家族的分类来提高检测效率。EC2提出了一种新的算法,用于发现大小不一的 Android 恶意软件系列从非常大到非常小的家族(微乎其微)。Fan等人提出了一种构建Fregraphs以表示属于同一家族的恶意软件样本的常见行为的新方法,对 Android 恶意软件进行分类,并根据Fregraph选择具有代表性的恶意软件示例。然后,他们设计并实施了一个新的检测系统FalDroid,它可以处理大规模Android恶意软件的家族分类,高精度和高效率。本文仅使用恶意软件的家族信息来改进 Bagging 算法来检测恶意软件。
由于机器学习的发展,它已广泛应用于Android恶意软件检测。但是,很难通过使用单个基础分类器(如支持矢量机 (SVM))来改进检测结果。因此,使用集成分类器进行检测已成为一种趋势。将具有独立决策能力的分类器相互组合的方法称为集成分类器(ensemble classifiers)。事实证明,集成分类器的预测能力比单个分类器的预测能力要强得多。在使用集合分类器的研究中,有两个方向:(一)是直接使用相关的组合分类器,如随机森林 (RF)、梯度提升决策树 (GBDT)、和阿达布斯特;(二)、是使用集成方法与单个分类器相结合,如提升、装袋和堆叠方法。Yerima 和 Sezer 提出了基于多层次分类器融合的检测框架 DroidFusion。此框架使用排序算法对低级训练分类模型进行排序,并选择最佳组合以产生最终决策结果。此外,在恶意软件检测领域,机器学习算法在特征提取、优化和软件检测方面具有显著优势。因此,本文选择改进Bagging算法,进一步提高多机学习的检测性能。
3、特征提取和选择
3.1、特征提取
Android 恶意软件检测的数据集是原始的 APK 文件,它是 Android 应用程序的安装包。为了提取相关特征,需要对 APK 文件进行分解以获取程序代码及其关键文件。因此,在本文中,APK 使用"安德罗卫士"进行分解 。获取 AndroidManifest .xml 和 Class.dex 文件并将 Class.dex 文件转换为 .smali 文件的工具,该文件更人性化,可作为字节代码的中间演示。
Android 活动文件包含执行程序和通信组件所需的所有权限。因此,本文从上述两个文档中提取了以下五个特征,如图所示:
- 权限:如果应用需要执行某些指定操作,则必须请求相应的权限
- 应用组件:应用程序组件是应用程序的基本构建基块,包括 activities、服务、发送器和接收器
- Intent 过滤器:Intent 用来处理组件之间的通信
- 敏感 API 调用:某些 API 呼叫允许调用智能手机上的敏感数据和资源
- 敏感的shell命令:某些命令可以获得 root 特权并执行危险操作

在实验中,为了降低资源消耗,提高检测效率,该特征以二元形式表示。如果应用程序中存在该特征,则该特征的相应位置标记为 1。否则,它被标记为 0,并且最终形成了图中显示的 0/1 的 eigenmatrix。

要进一步解释 eigenmatrix,假设样本数为m,特征数为n。因此,图的二维的艾根图2获得每个行表示示例,每个列表示一个特征。
3.2、特征选择
数据和特征决定了机器学习的上界,模型和算法只接近上界。特征选择是最大限度地从原始数据中提取特征,以便使用算法和模型。一般来说,特征选择包括以下四个步骤:
- 生成:生成特征的候选子集
- 评价:评估特征子集的质量
- 终止:决定何时停止生成过程
- 验证:检查特征子集是否有效
特征选择技术旨在更深入地了解数据,并最大限度地减少训练和测试阶段所需的计算量,以提高预测性能。它还概括了学习模式,以减少过拟合。通常,特征选择算法分为两种方法:(a) 特征搜索 (b) 特征子集评估。特征搜索是属性空间研究中广泛应用的技术之一。在机器学习领域,特征搜索可分为前向选择和后向淘汰。特征子集评估是一种广泛用于识别不相关和冗余属性的方法。
有三种类型的特征评估技术:筛选,根据差异或相关性对特征进行评价,并设置阈值以选择特征:包装,每次根据目标函数(通常是预测效果分数)选择或排除特征;嵌入是使用机器学习算法和模型进行训练的,并获得了各种特征的重量系数。特征根据从大到小的系数进行选择。相比之下,滤波器具有较高的计算效率,独立于其他分类学习方法,能有效排定特征的重要性。因此,本文选择了解压算法进行特征选择。
作为一种有效的特征选择算法,Relief 算法根据每个特征和类别的相关性分配不同的权重,重量小于一定阈值的特征将被删除。Relief 算法从训练集 D 中随机选择 样本 R,然后从与 R 相同的类别的样本中查找最近的邻居样本 H(称为 Near Hit),从称为 "Near Miss" 的不同类型的R样本中查找最近的邻居样本 M(C),然后根据以下规则更新每个特征的权重: \[ W(F)=W(F)- diff(F,R,H)/m+ diff(F,R,M(C))/m \tag{1} \] 其中 F 表示样本中的一个特征,m 表示样本数,diff(F, R1, R2) 函数表示示例 R 之间的差异1和样品 R2 在特征 F 和 M(C) 代表 C 类中最近的邻居样本。
如果特征上的 R 和 Near Hit 之间的距离小于 R 和 Near Miss 之间的距离,则表示该特征有利于区分类似种别的近邻和其他种别的近邻:然后,特征的权重将增加。相反,如果一个特征上的 R 和 Near Hit 之间的距离大于 R 和 Near Miss 之间的距离,则表明此特征对区分相似种别和不同种别的近邻有负面影响:然后,此特征的重量将减少。上述过程重复m次,最后获得每个特征的平均重量。因此,根据 Relief 算法计算的重量,本文筛选出小重量特征,有效提高了检测效率。参见部分详细描述。
4、集成检测方案
基于机器学习的传统 Android 恶意软件检测方案通常只使用单个基础分类器(如 SVM)进行检测,性能有限。但是,通过组合多个基础分类器或使用集成分类器可以取得更好的结果。
4.1、Bagging算法
Bagging 算法是并行集成算法最著名的代表。在集成算法中,Bagging方法是在原始训练集的随机子集上构建一类黑匣子评估器的多个实例,然后将这些评估器的预测结果组合在一起,形成最终预测结果。该算法的思路是使学习算法训练多轮:每轮训练集由随机从原始训练集中取出的 M 样本组成,训练样本可以在一轮训练中多次出现或未出现(即用替换进行采样),训练后可获得预测特征。最后,通过投票解决分类问题。著名的集成分类器 Rf, Bagging 算法加上决策树(DT)分类器, 是由布雷曼提出的 。Bagging算法的基本流程,如下算法流程所示,包括抽样、训练和分类。因此,本文提出的改进 Bagging 集成方案是抽样和最终投票分类的改进和创新。
输入:数据集 D, 迭代数 T, 采样数 n, 基础分类器 G(x)
输出:最终强分类器 f(x) (1) t = 1,2, ... (2) 训练集D随机采样 t 次,共抽取 m 次以获取包含 m 样本的采样子集 \(D_t\) (3) 使用样品集 \(D_t\) 训练基础分类器 \(G_t(x)\) (4) 如果是分类算法,则采用投票策略,即 T 基础分类器投出最多票数的类别类别或类别之一为最终分类。如果是回归算法,则采用算术平均值,即算术平均值对 T 弱分类器获得的回归结果进行,获得的值为最终模型输出
4.2、抽样策略
传统的 Bagging 集成算法使用随机取样策略,其中每个样本的选择概率相同,但在现实中,数据不平衡,不同恶意软件家族之间的有时差距很大,即样本数量随大小而变化很大。在这种情况下,采用随机抽样的抽样组样本分布极不平衡,有些家族数量众多,识别率相对较高,而另一些家族样本的识别率很低,从而降低了整体检测性能。但是,传统的 Bagging 算法只使用随机取样策略,表现上改进有限。其次,考虑到数据集中的每个样本都属于恶意软件家族,并且家族数量也各不相同,传统的 Bagging 算法很难考虑每个恶意家族。因此,为了充分利用每个恶意软件的家族信息并提高检测性能,本文在本文中增加了两种采样策略,如图所示,基于传统的 Bagging 算法:基于恶意软件家族的等量取样策略和基于恶意软件家族信息的家族取样策略。按相同家族数量进行采样意味着训练组中的每个家族以相同数量采集良性和恶意样本,样本不足的恶意家族通过超采样来构成样本数量。

家族抽样与恶意软件家族信息是基于每个样本的计算家族信息。每个恶意软件都属于特定的恶意软件家族,每个恶意软件都包含有关其家族的信息。在开始采样之前,对每个恶意软件家族进行家族信息估计器训练,以计算每个样本的家族信息。每个家族的所有恶意样本和训练集中的所有良性样本都发送到家族信息估算器进行训练,然后,每个样本中包含的家族信息作为输出。最后,每个家族应采集的样本数量根据每个恶意家族中所有样本的家族信息计算。其中,样本的恶意软件家族信息 MFI 表示样本属于家族的概率,MFI 值越高,属于家族的可能性就越大。MFI 计算公式如下: \[ MFI=Estimator(sample), \tag{2} \] Estimator()表示家族信息估计器
相反,恶意样本被误判为良性应用的可能性是 BFI。BFI 计算公式如下: \[ BFI = 1- MFI \tag{3} \] 因此,在某个家族中,所有样本被误判的概率越大,检测恶意家族就越困难,参与分类器训练所需的样本就越多。因此,本文设计了以下公式来计算要采集的样本数量: \[ N_i=[Num(family_i )*\sum_{j=1}^{Num(family_i)}BFI_{i,j}] \tag{4} \] 其中 \(N_i\) 表示要从 \(family_i\) 中取样的样本数量,表示样本 j 在家族中我被误判为良性应用的可能性,以及\(Num(family_i)\) 这两种新的抽样策略都基于恶意软件系列,家族数量决定取样数量。在随后的实验中,为了降低方案的复杂性,不再讨论基于恶意软件家族信息的家族抽样策略中家族信息估算器的选择,每个家族的信估计器采用相同的分类模型,分类模型取决于由组合方案集成的单个分类器。
4.3、改进的装袋组合检测方案
本文提出的组合检测方案中,每轮抽样将培养多个基础分类器,基础分类器的差异可以有效提高袋装方法的检测性能。因此,为了进一步提高基础分类器之间的差异,本文在传统的袋装算法的基础上增加了两种取样策略。因此,此方案分别使用三种采样策略,每个采样策略执行 N 轮。在每轮中,n 样本从原始训练集中作为训练子集进行选择,并选择总共 3N 训练子集。每个子集都对基础分类器进行训练,每个基础分类器仍然独立于其他子集。三种采样策略可以并行执行。
首先,我们在分组训练中执行采样。分别采用随机抽样策略,基于恶意软件家族的等号抽样策略和基于恶意软件家族信息的家族抽样策略,并进行回放 N 轮抽样,每个抽样方法获得 N 个训练子集 \(D_i, i = 1,2,……n\) 总共 3N 训练子集。接下来,为每个训练子集 \(T_i\) 训练基础分类器。
采用基于恶意软件家族信息的家族抽样策略时,应分别训练家族信息估计器,以便每个家族计算样本数量。最后,基础分类器通过根据样本的计算数量绘制样本进行训练,然后,使用具有最佳权重的加权投票策略将基础分类器组合成一个强分类器,以便测试组中的样本逐一通过每个基础分类器并执行加权投票以输出最终分类结果。在最终加权投票中,由于使用了三种不同的抽样策略,经过训练好的基础分类器的检测性能不同,不能简单地使用投票策略将每个分类器组合在一起,并且为每个分类器分配适当的权重,以进一步突出分类器之间的差异,从而提高检测效果。为了给每个基础分类器分配最佳权重,本文使用智能优化算法自动优化每个分类器的重量。因此,本文采用微分演化(DE)算法进行自适应优化。DE 算法是基于人口演变的随机搜索全球优化算法。它使用真实数字编码,包括三个基本操作:突变、交叉和选择。优化搜索以模仿生物种群之间的合作和竞争产生的启发式人口智能为指导。与其他演化算法相比,DE算法具有收敛快、操作简单、实现方便等优点。使用DE算法时,根据经验值和实验验证,将人群设置为40,进化数设置为30,缩放系数为0.5,交叉概率为0.3,分类器的精度为拟合特征,为了在实验结果中具有更大的稳定性和真实性, 使用五倍交叉验证。同时,当DE算法用于优化基础分类器的重量系数时,为了提高模型的学习效率,减少计算量,同时尽可能保证基础分类器之间的差异:同一采样算法获得的基础分类器具有相同的重量。
加权投票策略的规则是将每个基础分类器的预测票数乘以其权重系数,然后汇总每个类别的加权票数,所获得值的相应类别为最终分类结果。加权投票公式如下: \[ R(x_i) = sign(\sum_{j=1}^{3N}w_j * C_j(x_i)) \tag5 \] \(w_j\) 表示每个分类器的权重,\(C_j(x_i)\) 表示每个分类器 \(C_j\) 上 \(x_i\) 的预测结果
检测方案的整体流程见图4

集成检测方案的基本流程如下:
- 原始数据集分为训练数据集和测试数据集
- 对于训练数据集,使用三种采样策略进行 N 替换取样,每个采样方法分别获得 N 训练子集,共 3 个 N子集
- 每个训练子集都训练一个基础分类器,基础分类器相互独立
- 用于优化基础分类器的重量的差分演化算法
- 让每个基础分类器检测测试数据集中的每个样本,并加权并投票结果以输出每个样本的最终分类结果
5、评价
为了验证本文提出的方案,进行了以下实验。首先,我们在训练集中显示恶意家族样本的分布情况。然后,讨论由特征选择算法优化的特征。其次,验证加权投票策略的最佳权重是否改善了效果。最后,将所提出的方案与传统的分类方法进行比较,如SVM、RF、DT、K-最近的邻居(KNN)、逻辑回归(LR)、线性判别分析(LDA)、多层感知器(MLP)、RF(随机森林算法)、AdaBoost和GBDT(梯度提升决策树)。
5.1、数据集和选定特征
本文实验中使用的数据集包括恶意样品和良性样本。恶意样本主要来自 AMD 数据集包含 71 个家族,共包含 24,553 个恶意软件样本,广泛应用于 Android 恶意软件检测领域。良性样本来自谷歌游戏商店和 Apkpure 。同时,为了确保实验的有效性,良性数据集的应用包括体育、商业、游戏、教育、新闻等类别,并充分考虑了Android应用程序中的多种数据样本类型。
下一个实验随机从AMD数据集中随机抽取了8000个恶意样本,同时从良性数据集中随机抽取了8000个良性样本,共计16000个,形成实验数据集,并按7:3的比例分为训练和测试组。取样时,将原训练组的样品作为训练组进行,并分别采取5轮各取样方法。图5显示分组训练集中前 10 个恶意家族的分布。可见,恶意家族的样本分布极不均衡,第一的家族与第十的家族之间的差距已达十倍左右,更不用说少数恶意家族了。因此,缓解恶意样品的分别失衡是极其重要的。

此外,对实验中使用的特征进行了过滤,并且使用 Relief 算法计算每个特征的权重,并按大到小进行排名。然后,权重大于0.003的特征被选为最终输入特征。特征数量从89756个减少到789个,大大减少了特征冗余,提高了检测效率。
恶意软件检测是一个分类问题。分类问题存在四个常见指标:准确性、精度、召回率和F-score。恶意样本表示为positive (P)类,良性样本表示为negative (N)类。然后,获得四个评估数值:
- 真阳性 (TP): 正确预测为阳性的阳性样本数量
- 假阴性(FN):被错误地预测为阴性的阳性样本数量
- 假阳性(FP): 被错误地预测为阳性的阴性样本数量
- 真阴性 (TN): 正确预测为阴性的阴性样本数量
基于这些数值,以下方程计算四个常见指标: \[ Accuracy = (TP + TN)/(TP + FN + FP + TN) \tag6 \]
\[ Precision = TP / (TP + FP) \tag7 \]
\[ Recall = TP / (TP + FN) \tag8 \]
\[ F-score = \frac{2}{1/precision+1/recall} \tag9 \]
精度和召回率相互影响其调和平均值为F- score。
所有实验均在个人计算机上运行,配备 Intel (R) Core (TM) i7-9700 @ 3.0 GHz CPU,内存为 32 GB,并具有 Windows 10 64 位操作系统。用于评估的软件包括 Python 3.6.1 和 sklearn 0.23.2。
5.2、新抽样战略的执行情况
本文提出的FB2组合方案设计了两种新的基于恶意家族的抽样策略:基于恶意软件家族的等数取样策略和基于恶意软件家族信息的家族抽样策略。为了验证两种取样策略的性能,我们将它们与传统的 Bagging 集成算法进行比较,没有加权投票策略(每个分类器的权重设置为 1,这与传统的袋装集成算法一致),结果见表中1.
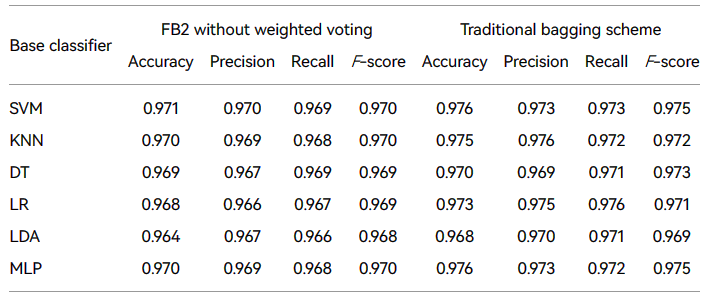
结果表明,传统的袋装算法在不使用权重的情况下取得了良好的性能,但FB2结成方案的表现得到了进一步的提高。因此,本文中基于恶意家族的两种取样策略有助于缓解恶意样品内部的不平衡,提高检测性能。
5.3、最佳投票权重的性能
本文提出的 Bagging 组合方案不仅设计了两种新的抽样策略,而且改进了每个最终基础分类器的组合,即采用加权投票策略进行最终整合。由于不同的采样策略和每轮抽样中选择的不同样本,最终训练的基础分类器也不同,因此每个基础分类器都有自己的偏好或差异。基础分类器之间的差异越明显,最终检测效果越好。因此,本文提出了一个加权投票策略,为每个基础分类器分配最佳权重,以更好地突出每个基础分类器的差异,进一步提高检测性能。本节使用 DE 算法比较 FB2 检测方案,以优化权重与没有正确权重的 FB2(即将每个基本分类器的重量设置为 1结果见表2。
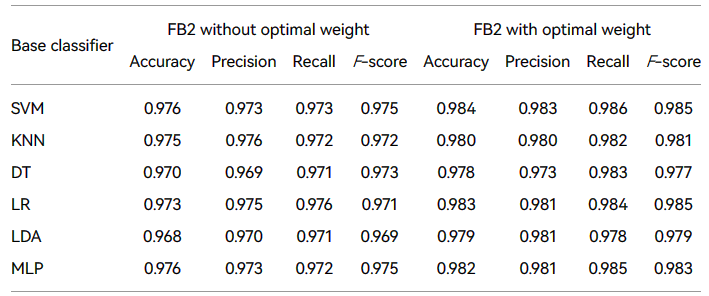
从表中可以看到,在给每个基础分类器分配最佳重量后,每个分类器的检测效果得到改善。在没有重量分配的情况下,FB2集成检测方案取得了良好的效果。但是,在使用差分演化算法为每个基础分类器分配最佳权重后,每个检测指标都得到了进一步改进。例如,精度的改进程度至少为 0.005,最多为 0.011。F- 分数至少提高了 0.004, 最高提高了 0.014 。因此,有必要为每个分类器分配适当的权重.
5.4、与基础分类器的比较
本节评估单个分类器 FB2 的性能改进。因此,FB2 与基础分类器(如 SVM、KNN、DT、LR、LDA 和 MLP)进行了比较。对于每个分类器的参数,使用默认值。表3显示每个基础分类器的实验结果和 FB2 检测结果。
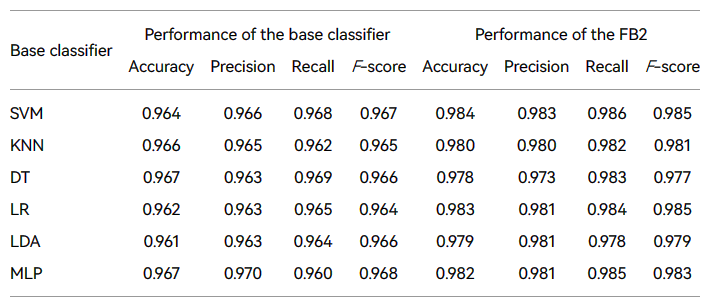
从表3,我们得出以下结论。首先,只有SVM、KNN、LR等单一分类型号作为分类器,才能达到良好的表现。然后,在使用 FB2 方案时,表现比单个分类模型显著提高。可以看出,对于所有基础分类器,FB2 使得所有四个效果指标的改进,准确性提高幅度从 1.1% 到 2.3% 不等。精度提高为1.1%至2.3%,F-score改进为0.9%至2.0%。
5.5、与集成分类器的比较
本节将 FB2 方案与现有集成分类器进行比较。为此,从上面显示的结果中选择结果最差的组,并与现有的集成分类器(如 RF、GBDT 和 AdaBoost)进行比较。对于每个分类器的参数,使用默认值。表4显示结果。虽然基础分类器作为分类器时取得了良好的性能,但与 RF 和其他集成分类器相比,其表现仍然较低。然而,FB2集成方案使用后,其性能得到进一步提高,与集成分类器相比有一定的提高。
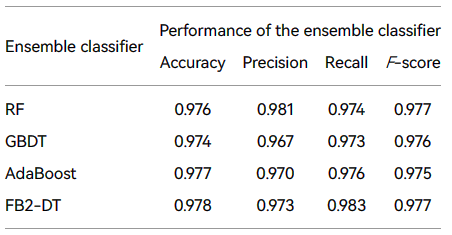
FB2 使用最无效的基础分类器 DT 与各种集成分类器进行比较。从表中显示的四种类型的评价指标可以看出4,虽然FB2-DT在所有指标中都没有领先,但在大多数情况下仍然是最好的。例如,准确性和F-得分都名列第一,分别为0.978和0.977。因此,一般来说,FB2在一定程度上优于上述三个集成分类器,这证明建议方案的有效性。
5.6、与传统装袋算法的比较
本节将所提出的 FB2 方案与各种单分类器下的传统 Bagging 算法进行比较:SVM、KNN、DT、LR 和 LDA。为了进行更公平的比较,所有分类器都使用默认参数,详细结果见表中。虽然传统的 Bagging 算法提高了单个分类器的性能,但本文提出的FB2方案的性能得到了进一步的提高。其中,精度提高 0.2%至1.2%。而且,F-分数提高了0.2%至1.4%。
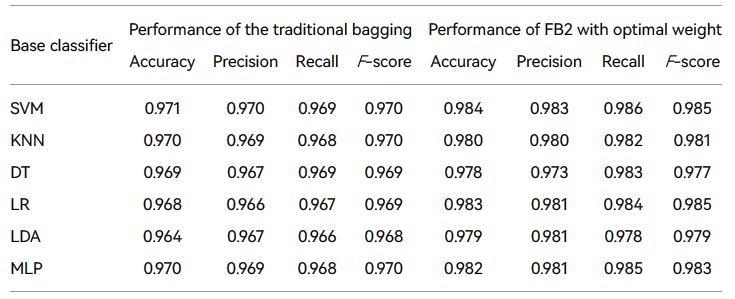
根据表1和表5,FB2 的性能比传统 Bagging 算法稍差,如果未使用加权投票策略,即未给每个基础分类器最佳权重。但是,在分配最佳权重后,FB2 有显著改进,超过了传统的 Bagging 算法,这进一步证明本文所提出的FB2方案是有效的。
5.7、模型可持续性分析
的确,基于机器学习的探测器肯定会老化,许多学者也在研究相关问题。
在一些论文中,为了缓解分类器老化问题,他们通过从Android API关系图中提取的API语义对分类器进行了训练。API 集群格式中提取的 API 语义可以进一步用于 Android 恶意软件分类器以减慢老化速度。
但是,本文使用五个特征进行恶意软件检测,并且不单独使用 API 的一个特征,并且每个特征也没有明确的调用关系,如 API,它可防止每种类型的特征的语义提取。还有,徐(K. Xu, Y. Li, R. Deng, K. Chen, and J. Xu, “DroidEvolver: self-evolving android malware detection system" )等人的研究,还基于 API 检测方案,该计划通过不断更新和演变 API 特征集来解决分类器的老化问题。这两种解决方案都使用单个特征进行检测,并且 API 会随着 Android 版本的迭代而更新,而其他特征基本上不会更改,因此仅使用单个特征进行检测将面临更严重的分类器故障问题。并且,使用许多不同类型的特征可以有效地减轻分类器的降解。本文使用了五个不同的特征,并在部分详细描述了这些特征。
并且,本文中使用的数据集是 AMD,并且样本是在相对较近的时间跨度内收集的。因此,数据集按年份分为七组进行测试,每个数据集被命名为 BM 加年。为了确保实验的公正性,选择了性能最差的基础分类器。为了进行更全面的评估,本文使用F分数指标,即可重复使用性和稳定性均基于F-core,详细结果见表6和7。
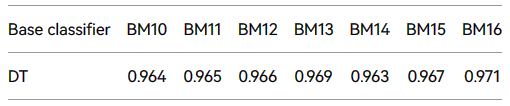
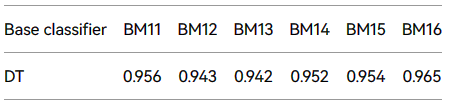
从表6和7,可以得出结论,具有多种特征的FB2在使用旧数据集进行训练和使用新数据集进行测试时,会取得良好的分类结果。FB2的平均可重复利用性约为96.7%,平均稳定性约为95.2%,均超过 DroidSpan。这表明,虽然基于单个动态特征的 DroidSpan 是可持续的,但基于多个特征的 FB2 非常适合恶意软件更新,并且具有良好的稳定性。
综上所述,本文提出的方案在使用许多不同类型的特征的情况下是可防止老化的。
6、结论
本文提出了一种新的基于恶意软件的家族 Bagging 集成方法 (FB2) 和 Android 恶意软件检测方案 (FB2Dorid)。此检测方案由以下步骤组成。首先,APK 文件被分解以提取特征。然后,使用 Relife 特征选择算法来选择一定数量的最重要特征。其次,提出两种采样策略,即等量取样和基于家族信息采样,旨在改进 Bagging 集成算法的采样策略。最后,将基本分类器与 FB2 相结合。
本文旨在验证FB2方案的可行性。实验结果表明,拟议的FB2方案取得了良好的效果。将来,作者将考虑设计新的集成算法,而不仅仅是改进现有的集成算法。此外,希望本文提出的若干抽样策略能真正帮助这一领域的学者。让他们在自己的方案中使用这些取样策略,有效减轻样本不平衡的影响,进一步提高恶意软件检测的准确性;其次,呼吁从事Android恶意软件研究的学者更加关注数据方向或样本失衡。恶意软件虽然增长较快,但与良性应用相比仍然过小,真实数据集和现实检测中的恶意样本数量非常少,恶意软件家族之间的分布差距较大,因此有必要缓解样本失衡。希望有更多的学者从本文中受到启发,提出更好的方案,消除样本失衡带来的负面影响。
将来,作者会考虑为每个训练子集选择适当的家族信息描述符,并将不同的权重分配给根据每个采样策略训练的基础分类器。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!