Multi-Class Imbalanced Graph Convolutional Network Learning
本文最后更新于:1 分钟前
原文链接:Multi-Class Imbalanced Graph Convolutional Network Learning (ijcai.org)
发布会议:2020年国际人工智能联合会议 —— IJCAI-PRICAI2020 (ijcai20.org)
摘要
网络数据通常采用偏类分布的帕累托原理(即80/20规则),即大多数顶点属于少数多数类,而少数类只包含少数实例。当存在不平衡的类分布时,现有的图嵌入学习倾向于偏向多数类中的节点,使得少数类中的节点缺乏训练。在本文中,我们提出了双正则化图卷积网络(DRGCN)来处理多类不平衡图,其中采用两种类型的正则化来处理类不平衡表示学习。为了保证所有类的平等代表性,我们提出了一种基于类条件的对抗训练过程,以促进标记节点的分离。同时,为了保持训练均衡(即保持所有类的拟合质量),我们通过最小化标记节点在嵌入空间中的差异,强制未标记节点与标记节点遵循相似的潜在分布。在真实世界的不平衡图上的实验表明DR-GCN在节点分类、图聚类和可视化方面优于最先进的方法。
介绍
图通常通常用于构建对象之间的直接和隐含关系。
例如:在社交网络中,相互关联的用户倾向于分享相似的兴趣,并共同代表一个独特的群体。因此,目前基于图的数据挖掘任务,如图表示学习或嵌入,主要侧重于从拓扑和属性内容的角度建模节点之间的相对亲和关系,这样的节点属于相同的类(例如,在嵌入空间中,可以将引文网络中的“研究区域”聚在一起。
在过去,大量的研究工作已被应用于监督或半监督图神经模型,包括最近提出的图卷积网络(GCN)及其许多变体。这些方法通常采用端到端学习范式,通过从输入图进行卷积表示学习后训练节点级多类分类器,即,每个节点通过聚集所有邻近区域的特征来形成自己的表现形式。尽管在文本分类、图像识别和推荐系统等许多应用领域取得了显著的性能,但现有方法往往假设输入类别分布接近或完全平衡,即,故意为每个类提供均衡的标签样本,确保多个类之间的表征学习均衡,从而完全避免类不平衡问题。
然而,许多真实世界的数据集自然地显示出高度倾斜的类分布,这是由于在这些真实世界的基于图的系统中,不同部分的不对称和不受限制的进化。
例如:
- 在NCI化学化合物图中,只有大约5%的分子在抗癌生物检测中是活性的
- 在Cora引文网络中, 26.8%的论文属于神经网络域,而规则学习和强化学习领域分别仅占7.9%和4.8%
当推广到类分布不均衡的图时,现有的GCN方法有过拟合多数类的倾向,导致对少数类的嵌入结果不理想。例如,图1展示了Cora引文网络上每个类的节点分类结果,其中L1和L6是少数类(也就是说,它们包含的实例比L0等其他多数类少得多)。我们观察到,在大多数情况下,在平衡设置下,来自所有7个类的节点都可以被正确分类,而在不平衡设置下,来自L1和L6这两个少数类的节点常常被错误分类。
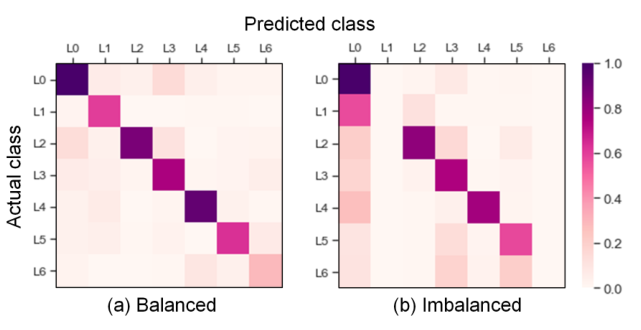
类不平衡学习的主要问题在于一个或多个类可能严重超过其他类,这极大地损害了大多数标准学习算法的性能。由于以下两个原因,这个问题在图结构数据的情况下更加严重:
- 拓扑相互作用:除了与每个图节点相关的丰富特性外,不同的节点之间可以有频繁的拓扑连接,这意味着每个节点的类分配不再简单地由其各自的特性决定,而是受到其连接节点的强烈影响
- 边界不清晰:图数据经常涉及多个高度倾斜的节点类,这使得很难平衡表示学习和准确识别类边界,因为一个特定类的学习可能会受到整个图中其他邻近类结构的严重影响,即,大多数类将主导节点之间的特性传播
在本文中,我们关注于一个一般化的多类非平衡图学习设置,并开发了一个新的图卷积网络,包含两种类型的正则化。
据我们所知,这是第一个研究节点级类不平衡图嵌入问题的图神经网络。
在提出的框架中:
- 我们首先使用一个两层图卷积网络导出分类平衡标签训练的节点表示
- 为了使不同类别的节点的表示学习更容易区分(明确边界),我们结合了一个有条件的对抗训练过程,以帮助分离不同类别的标记节点表示
- 此外,为了减少多数类的卷积训练对结构附近的少数类的负面传播影响,我们训练所有未标记节点,使其适合于学习的嵌入空间中训练良好的标记节点的相似数据分布,这促进了多数和少数群体之间的平衡训练
综上所述,我们的贡献是双重的:
- 我们提出研究一个考虑类分布的节点级图嵌入问题
- 我们提出DR-GCN,采用有条件的对抗训练和分布对齐来学习多数类和少数类的鲁棒节点表示
问题定义与准备
问题定义
给定一个具有不平衡节点的图,分布表示为
图:\(G= (V,E,X,L),\)
点集:\(V = \{v_i\}_{i = 1,...,n}\)
边集:\(E = \{e_{i,j}\}_{i,j=1,...,n;i≠j}\)
\(X\) 是矩阵 \(R^{n×m}\) 包含所有 \(n\) 个节点及其相关特征,\(X^i∈R^m\) 是 节点 \(v_i\) 的特征向量,其中 \(m\) 是图中唯一特征的数量
图 \(G\) 有多个类,用 \(L = {L_k} _{k=1,...,|L|}\) 表示,划分图 \(G\) 到 \(L\) 个类当中,其中每个类 \(L_k\) 中包含相似的节点
类分布可能是高度倾斜的,因为一个或多个类比其他类包含更多的节点,例如:\(|L_1| ≫ |L_2|\),在这种情况下,\(L_1\) 属于多数阶级,而 \(L_2\) 属于少数阶级。
本文的任务是用自然不平衡的类标签表示图 \(G\) 在 \(D\) 维语义空间 \(H^d\) 中的半监督训练,从整个节点填充中随机抽样几个带标签的实例。在训练过程中,节点空间 \(V = V_t ∪ V_u\) 实际上是类分布不平衡的有标记节点(\(V_t\))和未标记节点(\(V_u\))的并集。
条件生成式对抗网络
条件生成对抗网络 (cGAN) 由两个部分组成:
生成器 \(G(z|y)\),它映射噪声数据,从先验分布 \(z \sim p_z(z)\) 抽样到真实的数据分布空间
分配概率 \(D(x|y)\) 来表明是否是给定的真实训练样本或概率 \((1 - D(x|y))\) 来表明是一个假生成的样本(例如,\(x = G(z|y))\) 的判别器)
cGAN 的训练试图找到真假样本之间的最优区分,同时鼓励 \(G(z|y)\) 接近真实数据的分布。优化这两个方面的目标为: \[ \min_{G,\mathcal L} \max_D \mathcal L(D,G) = \mathbb E_{x\sim p_{data}(x)}\log D(x|y)+\mathbb E_{z\sim p_z(z)}[\log(1-D(G(z|y)))+\mathcal L_{reg}] \] 两者都以某些信息(例如:类标签)为条件,因此,我们能够生成与样本相关联的样本,并且能够很好地区分与变值赋值绑定的样本。
本文提出的多类不平衡图学习DR-GCN模型如图2所示,该模型包含如下三个协作组件。
方法
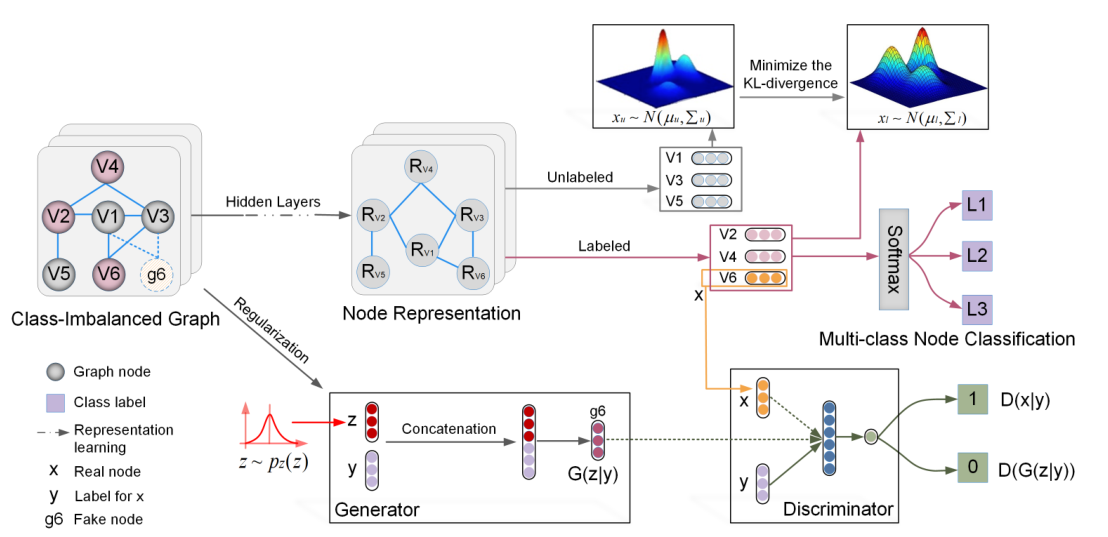
不平衡数据下的图卷积学习
本文采用两层图卷积网络对输入图 \(G\) 进行节点级表示学习,其中一阶和二阶邻域关系可依次建模为:
一阶: \[ O = \tilde A \ Relu(\tilde A XW_0)\ W_1 \] 其中,\(\tilde{A} = \tilde{D}^{-\frac{1}{2}}(A + I)\tilde{D}^{-\frac{1}{2}}\) 为归一化对称邻接矩阵,其中,\(I\) 是单位矩阵且\(\tilde{D}_{ii} = \sum_j (A + I)_{ij}\) 。\(W_0∈R^{m×r}~and~W_1 ∈ R^{r×d}\) 分别为第一和第二卷积层的学习参数,其中 \(r\) 为第一层隐含表示的维数。\(ReLU\) 是由 \(f(x) = max(0, x)\) 表示的激活函数。
第二层节点嵌入与通过 \(softmax\) 分类器进行多类节点分类训练的类数(\(d=|L|\))维数相同,方法为: \[ Z = softmax(O) = \frac{exp(O)}{\sum_i exp(O_i)} \\ \mathcal L_{gcn } = -\sum_{v_i \in V_l}\sum^d_{j=1}Y_{il} \ln Z_{ij} \] 公式4计算分类结果的交叉熵误差,其中 \(V_l\) 是一组标记训练节点,\(Y∈R^{n×|L|}\)是图节点的一个 one-hot 标签指标矩阵。
与现有文章中刻意平衡的训练样本相反,我们关注更实际的情况下,自然类不平衡分布,即从整个群体中随机抽取节点构建 \(V_l\)。然而,如图1所示,传统的GCN无法处理类不平衡图,因此我们引入了两种类型的正则化训练来缓解这个问题。
类条件对抗正则化层
在不平衡环境下采用标准卷积学习,少数类容易被附近的多数类同化。为了加强不同类别的分离,我们对所有被标记节点进行有条件的对抗训练。
对于每个具有类指示 \(y\) (一个 one-hot向量)的真实训练样本 \(x∈V_l\) (例如,\(v_6\)),生成器将从先验正态分布 \(z \sim pz(z)\) 产生的噪声 \(z\) 作为输入,然后通过与标准多层感知器(MLP)进行连接和学习后转换为一个为伪样本 \(x\)(例如,\(g_6\))。另一方面,鉴别器学习在一定条件下对真假样本进行分类。为了提高生成器的学习能力,我们添加了一个正则化,使生成的伪节点可以通过以下方法重建图中各自的邻域关系(如 \(g_6\) 具有与 \(v_6\) 相似的拓扑结构): \[ L_{reg} = \sum _{v_i∈N(x)} \left \| h_{g_x} - h_{v_i} \right \|_2 \] 公式(5) 表示 \(x\) 与相邻结点 \(N(x)\) 之间的成对距离。最后,对抗性训练目标为: \[ \min_{G,\mathcal L} \max_D \mathcal L(D,G) = \mathbb E_{x\sim p_{data}(x)}\log D(x|y)+\mathbb E_{z\sim p_z(z)}[\log(1-D(G(z|y)))+\mathcal L_{reg}] \] 公式(6) 采用小批量的方式进行训练,其中有平衡的训练类。对抗性训练的主要思想是:当鉴别器学习正确分类不同类别的训练样本时,它会反过来鼓励卷积层学习不同类别节点的区别表示。
潜在分布对齐正则化层
虽然对抗训练可以促进标记节点的区分结果,但它可能导致标记空间内的过拟合,使未标记空间中的少数类缺乏训练。因此,我们提出在有标记节点和无标记节点表示之间进行分布对齐训练,其中,假设对未标记空间中的多个不平衡类进行平衡卷积训练,以匹配标记空间中训练良好的类不平衡节点。
我们假设在标记空间中的表示(如:\(h_{x_l}∈H^d, x_l∈V_l\))和未标记空间(如:\(h_{x_u}∈H^d, x_u∈V_u\))遵循二维多元高斯分布即 \(x_l\sim N(µ_l,Σ_l)\) 和 \(x_u\sim N(µ_u,Σ_u)\),其中它们的概率密度函数为: \[ \begin{gathered} p\left(x_{l} ; \mu_{l}, \Sigma_{l}\right)=\frac{\exp \left(-\frac{1}{2}\left(x_{l}-\mu_{l}\right)^{T} \Sigma_{l}^{-1}\left(x_{l}-\mu_{l}\right)\right)}{(2 \pi) d / 2\left|\Sigma_{l}\right|^{1 / 2}} \\ p\left(x_{u} ; \mu_{u}, \Sigma_{u}\right)=\frac{\exp \left(-\frac{1}{2}\left(x_{u}-\mu_{u}\right)^{T} \Sigma_{u}^{-1}\left(x_{u}-\mu_{u}\right)\right)}{(2 \pi)^{d / 2}\left|\Sigma_{u}\right|^{1 / 2}} \end{gathered} \]
其中,\(µ_l,µ_u∈R^d\) 和 \(Σ_l,Σ_u∈R^{d×d}\) 分别为均值和协方差。在这种情况下:
类标签彼此之间没有关联,例如 (7) 和 (8) 可以分别表示为具有对角协方差 \(Σ_l=diag(σ^2_{l,1}, σ^2_{l,2},· · ·, σ^2_{l,d})\) 和 的 \(Σ_u=diag(σ^2_{u,1}, σ^2_{u,2},· · ·, σ^2_{u,d})\) 独立高斯分布的乘积: \[ \begin{aligned} &p\left(x_{l} ; \mu_{l}, \Sigma_{l}\right)=\prod_{k=1}^{d} \frac{1}{\sqrt{2 \pi} \sigma_{l, k}} \exp \left(-\frac{\left(x_{l, k}-\mu_{l, k}\right)^{2}}{2 \sigma_{l, k}^{2}}\right) \\ &p\left(x_{u} ; \mu_{u}, \Sigma_{u}\right)=\prod_{k=1}^{d} \frac{1}{\sqrt{2 \pi} \sigma_{u, k}} \exp \left(-\frac{\left(x_{u, k}-\mu_{u, k}\right)^{2}}{2 \sigma_{u, k}^{2}}\right) \end{aligned} \] 其中,参数可由带标签样本和未带标签样本近似为 : \[ \begin{aligned} \mu_{l}=& \frac{1}{\left|\mathbf{V}_{l}\right|} \sum_{v_{i} \in \mathbf{V}_{l}} \mathbf{h}_{v_{i}}, \mu_{u}=\frac{1}{\left|\mathbf{V}_{u}\right|} \sum_{v_{j} \in \mathbf{V}_{u}} \mathbf{h}_{v_{j}} \\ \Sigma_{l}=& \frac{1}{\left|\mathbf{V}_{l}\right|} \sum_{v_{i} \in \mathbf{V}_{l}}\left(\mathbf{h}_{v_{i}}-\mu_{l}\right)^{2}, \Sigma_{u}=\frac{1}{\left|\mathbf{V}_{u}\right|} \sum_{v_{j} \in \mathbf{V}_{u}}\left(\mathbf{h}_{v_{j}}-\mu_{u}\right)^{2} \end{aligned} \] 基于 Kullback-Leibler 散度(均为 \(Σ_l\) 和 \(Σ_u\) 非奇异),我们最终最小化 \(x_l\sim N(µ_l,Σ_l)\) 和 \(x_u\sim N(µ_u,Σ_u)\)之间的差异为: \[ \begin{array}{r} \mathcal{L}_{\text {dist }}=\frac{1}{2}\left(\log \frac{\left|\Sigma_{u}\right|}{\left|\Sigma_{l}\right|}-d+\operatorname{tr}\left(\Sigma_{u}^{-1} \Sigma_{l}\right)+\right. \left.\left(\mu_{u}-\mu_{l}\right)^{T} \Sigma_{u}^{-1}\left(\mu_{u}-\mu_{l}\right)\right) \end{array} \]
总流程
输入:图 \(G= (V,E,X,L),\)
输出:节点嵌入 \(O∈R^{n×d}\)
初始化:\(j= 1\),训练历期 \(I\) 和 \(M\),批大小\(N\),通过公式2卷积层都可以训练的标记集 \(V_l\) 和未标记集 \(V_u\)
\(while ~ j ≤ I ~ do\)
O ← 通过式(2)学习卷积表示
\(N(µ_l,Σ_l)\) ← 从 \(v_l\) 中学习潜在分布
\(N(µ_u,Σ_u)\) ← 从 \(v_u\) 中学习潜在分布
\(L\) ← 由式(14)计算分类损失
\([W_0,W_1]\) ← 更新式(2)中网络参数
\(for ~ τ ∈ [1,M)\)
\(x_∆\) ← 从 \(v_l\) 中采样一批 \(N\) 个类平衡训练样本,其中 \(x_∆\) 是可训练的;
\(z_∆\) ← 从 \(z \sim pz(z)\) 采样一批N噪声数据数据;
用它的随机梯度(其中 \(x_k∈x∆\) 和 \(z_k∈z∆\))更新生成器: \[ \begin{gathered} \nabla \frac{1}{N} \sum_{k=0}^{N}\left[\log D\left(x_{k} \mid y_{k}\right)+\log \left(1-D\left(G\left(z_{k} \mid y_{k}\right)\right)\right)\right. \left.+\sum_{v_{i} \in \mathbf{N}\left(x_{k}\right)}\left\|\mathbf{h}_{g_{x_{k}}}-\mathbf{h}_{v_{i}}\right\|_{2}\right] \end{gathered} \] 用随机梯度更新鉴别器和卷积层(如 \(W_0\) 和 \(W_1\)): \[ \nabla \frac{1}{N} \sum_{k=0}^{N}\left[\log D\left(x_{k} \mid y_{k}\right)+\log \left(1-D\left(G\left(z_{k} \mid y_{k}\right)\right)\right)\right] \] \(for ~ end\)
\(j = j + 1\)
\(while ~ end\)
算法训练与优化
算法1说明了所提出的框架。DR-GCN通过三个部分进行训练:半监督式的标准卷积训练、促进不同类的区分表示的条件对抗性训练和维持多数类和少数类之间学习平衡的分布对齐训练。为了避免分布对齐训练对标准表示卷积学习带来的强约束,我们将它们结合在一起: \[ L_{dist} = (1−α)L_{gcn} + αL_{dist} \] 其中α的设置是为了平衡训练的两个方面。
实验装置
数据集:我们使用了四种广泛使用的基准图数据集,包括Cora, Citeseer, Pubmed和DBLP。
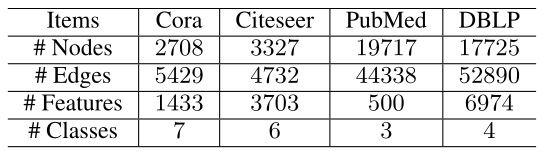
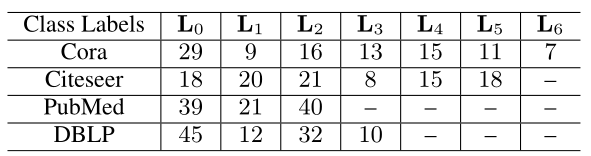
数据统计汇总如表1所示。所有四个图都是自然的类不平衡,它们的类分布如表2所示。我们可以观察到,对于每个图,某些类所包含的节点数量要比其他类少得多。在Cora数据集中,29%的图节点属于 \(L_0\),只有7%的图节点属于 \(L_6\)。
比较的方法:我们将其与以下几种最先进的嵌入方法进行比较,包括 DeepWalk 学习节点表示基于 \(SkipGram\) 模型、\(Graph-LSTM\)、标准\(GCN\)、\(GCN\) 结合随机欠采样 (\(GCN_{RUS}\)) 和 \(GAT\),所有学习节点表示从图结构和内容与基于频谱的卷积滤波器。我们还比较了两个变种 \(DR-GCN_{gan}\) 和 \(DR-GCN_{dist}\),,它们分别包含了类条件对抗性正则化和潜在分布对准正则化。
设置:我们分别通过节点分类、图聚类和可视化对模型进行评估。根据标准GCN方法使用的标签率,我们从整个图中随机抽取 3% 的节点进行训练。剩下的节点被划分为验证和测试集,其中10%用于超参数优化,90%分别用于测试。对于节点分类,效果根据 Accuracy (Acc) 和 AUC 评分计算。每个实验重复10次,我们用标准误差报告平均值。对于图聚类任务,使用 K−means 算法,以学习到的节点嵌入作为输入,通过四个度量计算效果,包括精度(Acc)、精度、F1-score (F1) 和 标准化互信息(NMI)。对于基于GCN的方法,我们设置隐藏嵌入大小 \(r\) 为10,辍学率为0.3,L2范数正则化权衰减为 0.03,梯度算法的学习率为 0.002。我们设置最大训练周期为1000,早期停止为200。我们设置最大训练周期为1000,早期停止为200。在我们的方法中,\(M\)、\(N\) 和 \(α\) 的默认值分别设置为1、\(|V_l|/2\) 和0.7,其中 \(|V_l|\) 是标记节点的总数。
节点的分类
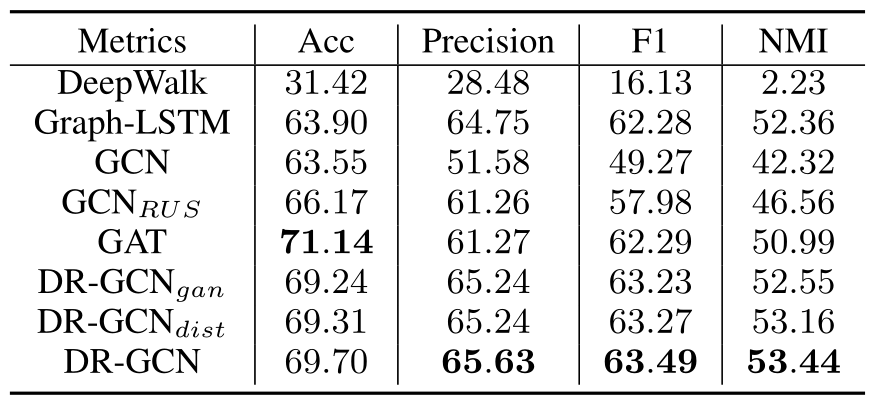
分类结果如表3所示。我们可以观察到 \(DR-GCN_{gan}\) 和 \(DR-GCN_{dist}\) 都比GCN表现更好,这证明了引入的类条件对抗正则化和潜在分布对齐正则化对类不平衡节点分类的有效性。此外,\(DR-GCN\) 模型在所有四个类不平衡图上的表现均优于随机欠采样方法 \(GCN_{RUS}\) 和 \(GAT\)、\(GraphLSTM\)等先进方法,验证了该方法的优越性。
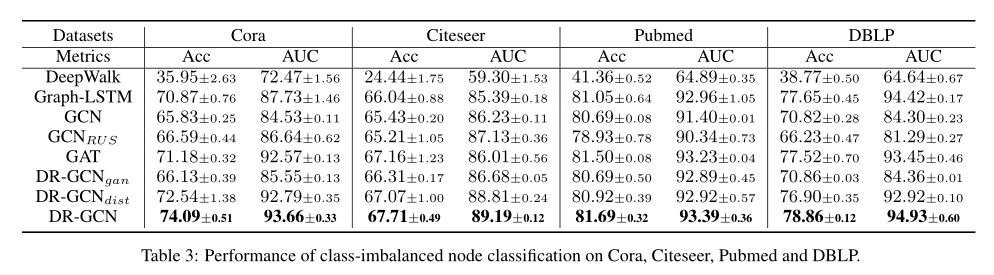
不同的不平衡率:我们在 Cora 和Citeseer上测试了 \(DRGCN\) 训练比例在少数类和多数类之间的表现:对于Cora数据集,我们假设 \(L_1\) 和 \(L_6\) 是少数类,\(L_0\) 是多数类。类似地,我们假设 \(L_3\) 是 Citeseer 的少数类,\(L_1\) 和\(L_2\) 是多数类。然后,我们改变少数类和多数类的训练样本的比例,并相应地改变多数类的比例(例如,在Cora的表2中,少数类和多数类的原始训练比例分别为(9+7)和29%。如果少数阶级的比率增加到18%,那么多数阶级的比率就会减少到27%)。从图3中可以看出,\(DR-GCN\) 在不同少数类比例下的表现明显优于 \(GCN\),说明我们的模型对班级不平衡的图学习具有更好的鲁棒性。
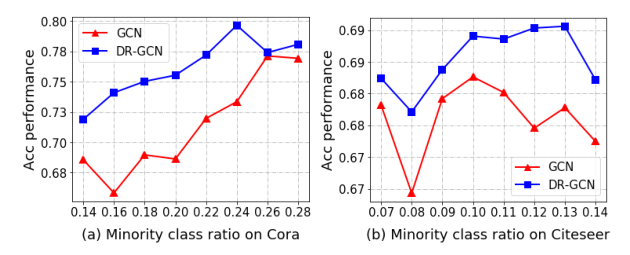
参数分析:图4显示了参数α在公式14中平衡标准卷积学习和分布对齐训练的影响。在Cora和Citeseer数据集上,随着α值的增大,分类性能先上升后下降。
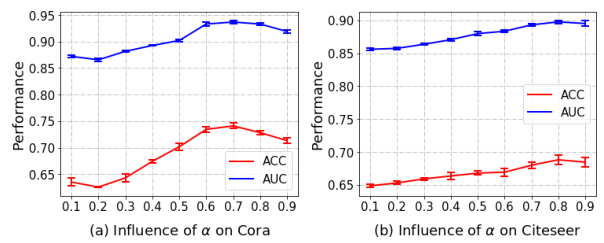
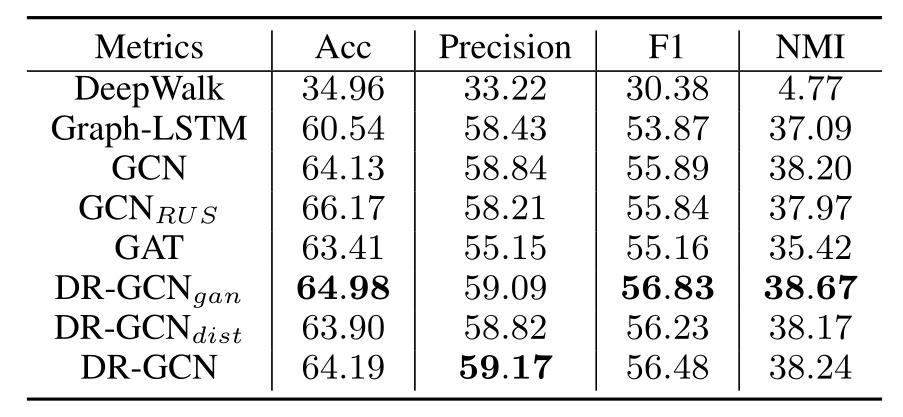
图聚类
表4和表5报告了所有基线的聚类结果。在Cora和Citeseer数据集上,我们可以观察到DR-GCN始终优于GCN,这再次验证了我们的正则化学习过程的好处。虽然GA T在Cora上的Acc性能略好于其他算法,但在Cora和Citeseer数据集上,GAT、F1和NMI性能均较DR-GCN差。聚类结果表明了我们提出的学习框架的优越性。
虽然GAT在Cora上的Acc性能略好于其他算法,但在Cora和Citeseer数据集上,GAT的Precision、F1和NMI性能均较DR-GCN差,聚类结果表明了我们提出的学习框架的优越性。
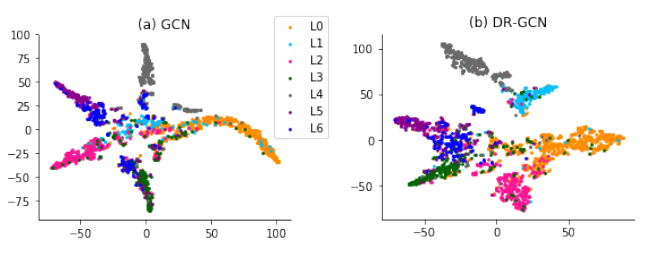
图形可视化
图5显示了Cora数据集上的二维节点嵌入可视化结果。与GCN相比,\(DR-GCN\) 学习了更多的判别型节点嵌入,特别是对于少数类,如 \(L_1\) 和 \(L_6\),分别占节点总数的9%和7%。
总结
真实世界的图结构数据通常呈现高度扭曲的类分布。在学习类不平衡图时,最关键的挑战是节点具有很强的拓扑依赖性,导致现有的网络表示学习方法在少数类上表现不佳。在本文中,我们提出了一种新的双正则化图卷积网络,该网络包含有条件的对抗训练以增强不同类中的节点分离,以及分布对齐训练以加强多数类和少数类之间的均衡学习。
我们进行了广泛的比较研究来评估节点分类和无监督图聚类的提议框架。实验结果的验证、可视化和比较表明,本文提出的DR-GCN模型能够有效地处理类分布自然不平衡的图数据。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!